
Every System You’ve Ever Built Has Only Four Knobs
And you’re always turning one at the cost of another.

I keep running into the same problems wearing different costumes.
Why a database shards data the same way a team splits up work. Why putting everything on one server feels like keeping all your notes in one app. Why a meeting where everyone has to agree before shipping anything looks exactly like a distributed transaction.
I spent a while thinking these were separate problems. They’re not. They’re four trade-offs that show up at every layer of every system — from CPU caches to org charts. Once I started seeing them, I couldn’t stop.
Four knobs. You can turn any of them. But every turn costs you something.
1. Granularity — Break It Down, Pay the Tax
The smaller you break up work, the more evenly you can spread it around. But each piece has overhead. Scheduling, tracking, coordinating. More pieces, more management.
Think about it like this. You have four people and one giant task. One person grinds through it while three watch. Inefficient. Now break that task into sixteen subtasks — everyone’s busy, work finishes faster. But now someone has to manage sixteen things instead of one.
This shows up everywhere:
Kubernetes: One massive pod vs. dozens of microservices
Databases: One complex query vs. many simple ones
Your to-do list: “Build the feature” vs. twelve atomic tasks with check boxes
That to-do list thing isn’t a joke. I’ve absolutely spent more time decomposing tasks into sub-tasks than it would’ve taken to just… do the thing. The overhead of granularity is real, even in your own head.
In code, it looks like this:
// Coarse: one connection handles everything sequentially
fn handle_all(requests: Vec<Request>) {
for req in requests {
process(req); // Other threads sit idle
}
}
// Fine: each request is a separate task
for req in requests {
tokio::spawn(async move {
process(req).await;
});
}
// Overhead: task creation, scheduling, memory per taskAnd at the infrastructure layer, the same thing:

Same trade-off. Different costume.
The rule: You sacrifice simplicity, but gain efficiency.
2. Locality — Close Is Fast, Spread Out Survives
Keeping things close together is fast. Same machine, same memory, same room — communication is nearly instant. But if that one location goes down, everything goes with it.
The simplest version of this:
Your app, your database, and your cache all live on one server. Lightning fast — no network hops, no serialization overhead. Latency measured in microseconds. Beautiful.
Then that server catches fire.
Distribute them across three machines and now you’ve got network latency on every call. Slower. But when one machine dies, the others keep going.
This one resonates beyond infrastructure. It’s the same trade-off as:
Remote teams vs. co-located teams — co-located is faster, remote is more resilient to office closures, life events, geography
All your notes in one app vs. spread across tools — one app is convenient until it shuts down and takes everything with it
Concentration vs. diversification — every financial advisor’s favorite speech
In code, it’s the difference between a HashMap and a network call:
// Local: in-memory HashMap — fast, not resilient
let sessions: HashMap<SessionId, Session> = HashMap::new();
// Server restart = all sessions lost
// Distributed: Redis cluster — slower, resilient
let session = redis.get(session_id).await?;
// Network hop, but survives server restartsAnd at the architecture layer:
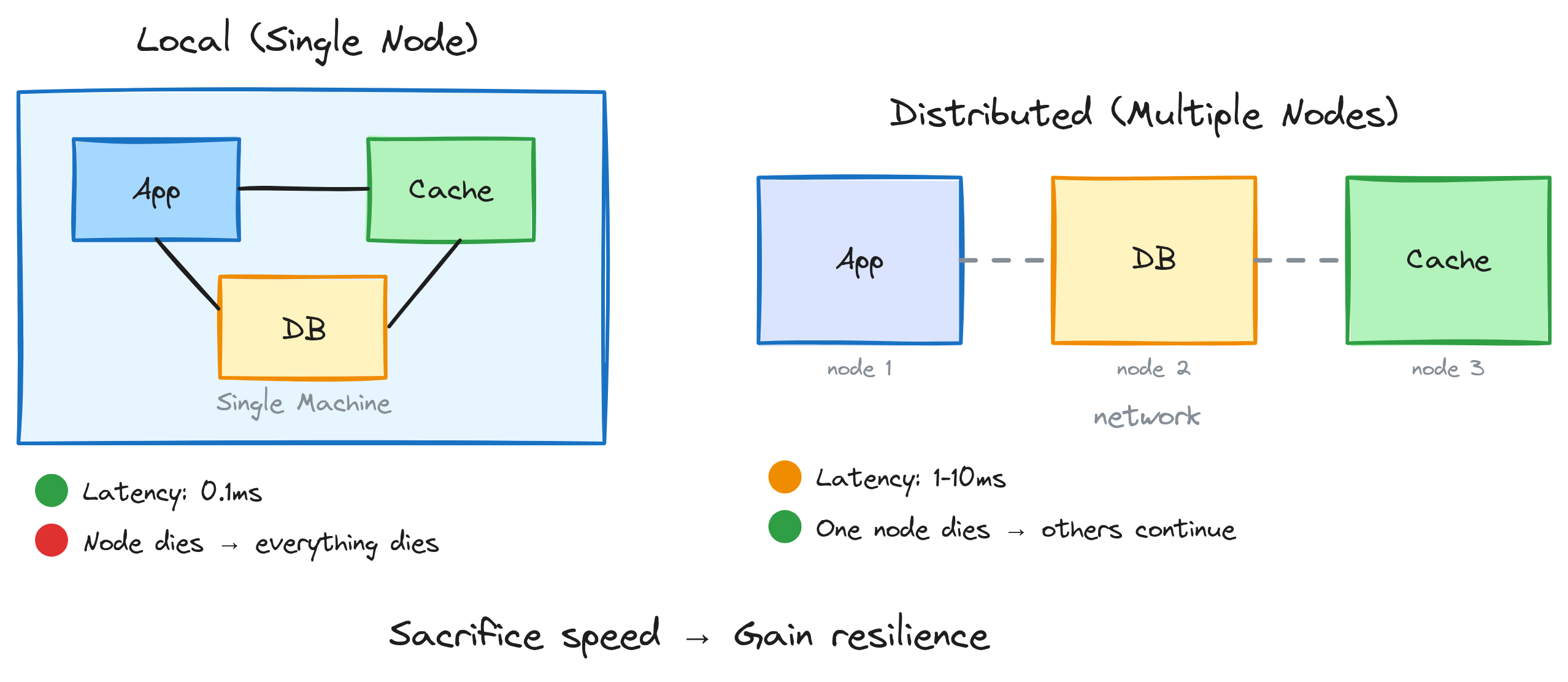
Same trade-off. Different layer.
The rule: You sacrifice speed, but gain resilience.
3. Coordination — Talk More, Move Slower
The more your workers communicate and agree before acting, the more consistent the outcome. But coordination is expensive. Everyone has to wait for everyone else.
Strong coordination looks like a database transaction — every node confirms the write before anyone moves on. Correct, consistent, slow. You’re only as fast as your slowest participant.
Weak coordination looks like “everyone do your thing, we’ll reconcile later.” Fast, high throughput, but nodes temporarily disagree. Your read might be stale. Your count might be off. For a while.
Real-world version: ever been in a meeting where everyone had to agree before anything could ship? That’s strong coordination. Consistent outcomes, glacial pace. Now compare that to a team where people ship independently and sync up async. Faster, but occasionally someone ships something that conflicts with what someone else just shipped.
Neither is wrong. It depends on what you’re optimizing for.
Correctness critical (financial transactions, inventory counts) → coordinate more
Throughput critical (social media feeds, analytics) → coordinate less
In code, you can literally see the spectrum:
// High coordination: Mutex — consistent, slower
let counter = Arc::new(Mutex::new(0));
{
let mut c = counter.lock().unwrap(); // Wait for lock
*c += 1;
}
// Less coordination: Atomic — faster, limited operations
let counter = AtomicU64::new(0);
counter.fetch_add(1, Ordering::Relaxed); // No waiting
// Even less: per-thread counters, merge later
thread_local! { static COUNT: Cell<u64> = Cell::new(0); }
// Fast, but only eventually consistentAnd at the architecture layer, the same spectrum plays out across nodes:
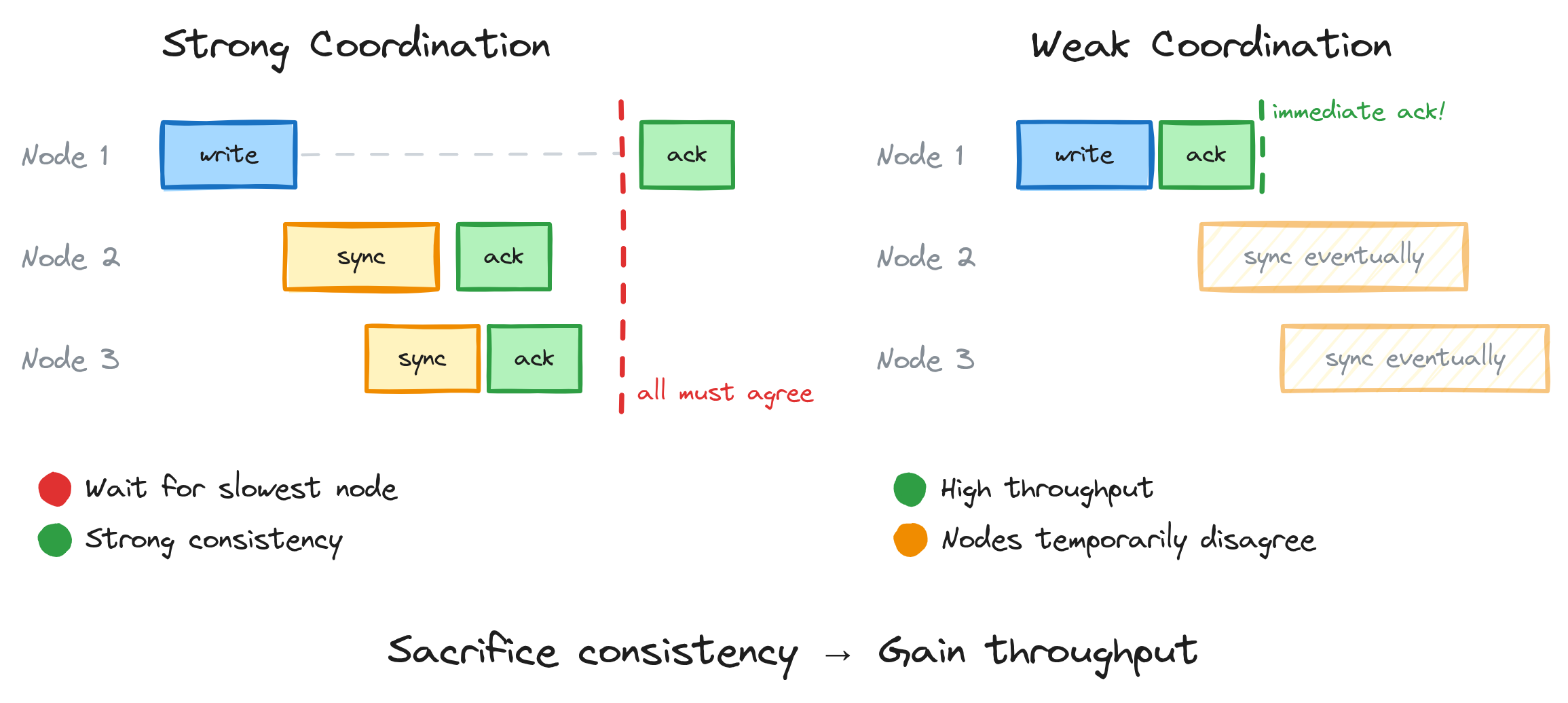
Same spectrum. Mutex to gossip protocol. Lock to eventual consistency.
The rule: You sacrifice consistency, but gain throughput.
4. Isolation — Walls Have a Cost
More isolation means failures stay contained. A bug in one service doesn’t cascade into everything else. But isolation has overhead — more boundaries to maintain, more complexity to manage, more inter-service communication to design.
The monolith: one process, one deployment, everything shares everything. Simple. Easy to reason about. But a bug in your email service takes down your payment processing.
Microservices: each service is its own little world. Email crashes? Payments keep running. But now you have network boundaries, service discovery, distributed tracing, and a whole new category of failure modes to think about.
This is also:
One person doing five jobs vs. five specialists — the generalist is a single point of failure for all five functions
Shared database vs. database-per-service — shared is simpler until one team’s migration breaks everyone’s queries
Single-region vs. multi-region — one region is straightforward until that region has an outage
In code, it’s the difference between shared state and a process boundary:
// Shared fate: threads in one process
let data = Arc::new(Mutex::new(vec![]));
thread::spawn({
let data = data.clone();
move || {
let mut d = data.lock().unwrap();
panic!(”oops”); // Mutex now poisoned for everyone
}
});
// Isolated: separate processes
Command::new(”./worker”)
.spawn()
.expect(”failed to spawn”);
// Worker crashes? Main process is fine. Restart the worker.And at the architecture layer:
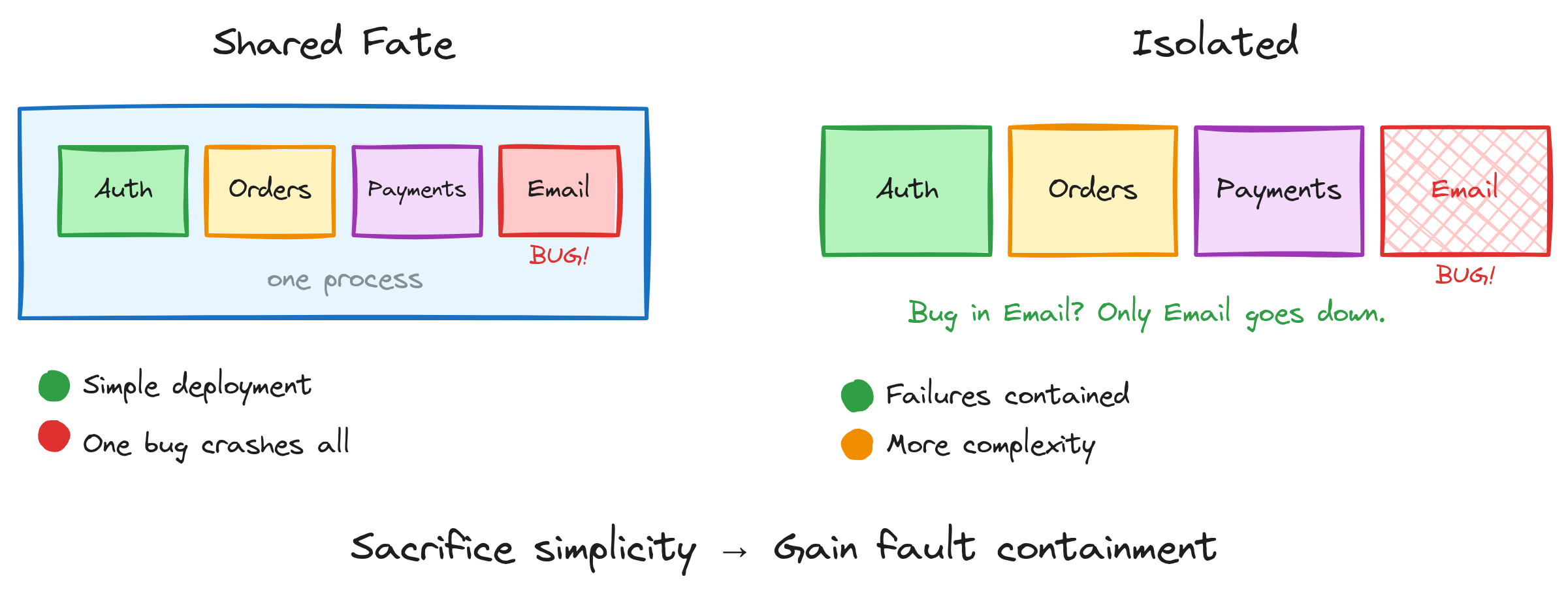
The rule: You sacrifice simplicity, but gain fault containment.
The Uncomfortable Truth
There’s no right answer. There are only trade-offs appropriate for your constraints.
Every system you’ve ever touched sits somewhere on each of these four spectrums. And the interesting part isn’t where it sits — it’s whether anyone made that choice deliberately, or whether the system just… ended up there.
Granularity: You give up Simplicity and you gain Efficiency
Locality: You give up Speed and you gain Resilience
Coordination: You give up Consistency and you gain Throughput
Isolation: You give up Simplicity and you gain Fault containment
The next time you’re staring at an architecture decision — or honestly, any decision about how to organize work — ask yourself: which knob am I turning, and what’s it costing me?
If you can answer that clearly, you probably have a good design.
If you can’t, you probably have a meeting to schedule.